[개념]기초 자료구조
자료구조 기초.
✍탐색(search)
-
많은 양의 데이터 중에서 원하는 데이터를 찾는 과정이다.
-
그래프, 트리등 자료 구조안에서 탐색을 하는 문제를 자주 다룬다.
-
대표적인
탐색 알고리즘(DFS/BFS)이 있다.
탐색 알고리즘(DFS/BFS)를 알아보기전 기초 자료구조에 대해서 알아보자.
📚 자료구조란 ?
데이터를 표현하고 관리하고 처리하기 위한 구조 이다.
그 중 스택 & 큐는 자료구조의 기초 개념이다. 삽입(push)와 삭제( pop)라는 함수로 구성이 되어지고,
그 외 오버플로우(overflow), 언더플로우(underflow)에 대해서도 고민을 해야한다.
스택(stack)
박스를 쌓고 빼는 법과 원리가 유사하다.
선입후출(Fist In Last Out) / 후입선출(Last In First Out)
stack = []
#삽입(5) - 삽입(2) - 삽입(3) - 삽입(7) - 삭제 - 삽입(1) - 삽입(4) - 삭제()
stack.append(5)
stack.append(2)
stack.append(3)
stack.append(7)
stack.pop()
stack.append(1)
stack.append(4)
stack.pop()
print(stack)
print(stack[::-1])
output
[5, 2, 3, 1]
[1, 3, 2, 5]
⭐ 파이썬에서 스택(stack)을 구현할 때 별도의 라이브러리를 사용할 필요가 없다.
기본 리스트의 함수 append와 pop이 스택 자료구조와 동일하게 동작하기 때문이다.
큐(queue)
대기줄의 원리가 유사.
선입선출(First In First Out)
from collection import deque
#큐(Queue) 구현을 위해 deque 라이브러리 사용
queue = deque()
#삽입(5) - 삽입(2) - 삽입(3) - 삽입(7) - 삭제() - 삽입(1) - 삽입(4) - 삭제()
queue.append(5)
queue.append(2)
queue.append(3)
queue.append(7)
queue.popleft()
queue.append(1)
queue.append(4)
queue.popleft()
print(queue)
queue.reverse()
print(queue)
output
deque([3, 7, 1, 4])
deque([4, 1, 3, 7])
⭐ 파이썬에 큐(queue)를 구현할 때 collection 모듈에서 제공하는 deque 자료구조를 활용하면 좋다.
deque는 스택과 큐의 장점을 모두 채택한 것,
데이터를 넣고 빼는 속도가 리스트 자료형에 비해 효율적이고, queue 라이브러리를 이용하는 것보다 더 간단하다.
재귀함수(recursive function)
재귀함수는 스택 자료구조를 이용하여 데이터를 처리한다.
나무위키를 보다 갑자기 생각 난 비유,
꿈에서 꾸는 꿈에서 꾸는 꿈에서 꾸는 꿈에서 꾸는 꿈에서 꾸는 꿈…..을 깨어나려면
가장 depth가 깊은 꿈에서 부터 차례로 깨어나야 한다 ! ! 재귀함수 원리라 비슷한 듯? ㅎㅎ
DFS/BFS
DFS(Depth-Fist-Search)
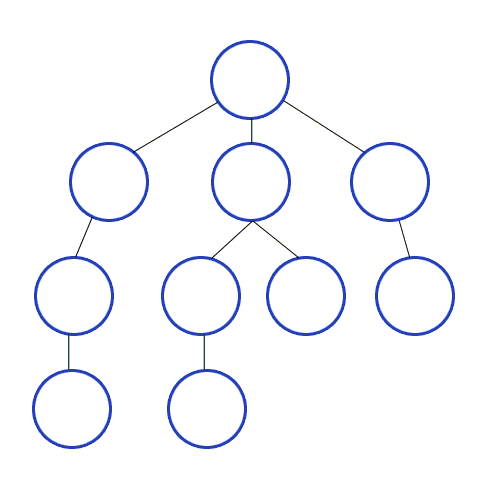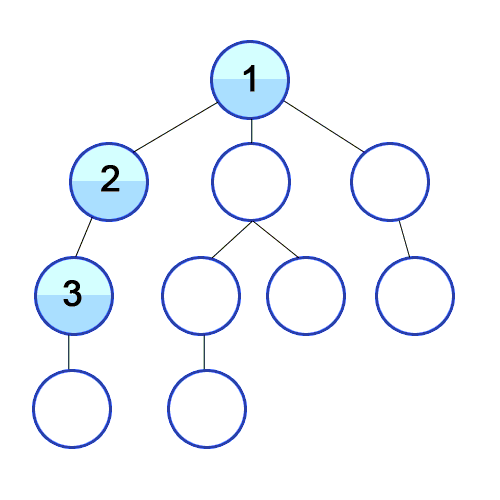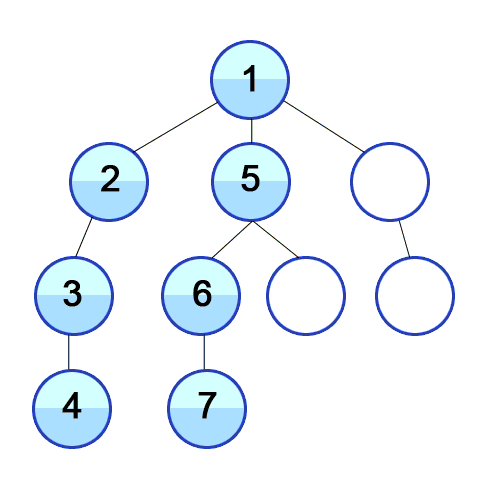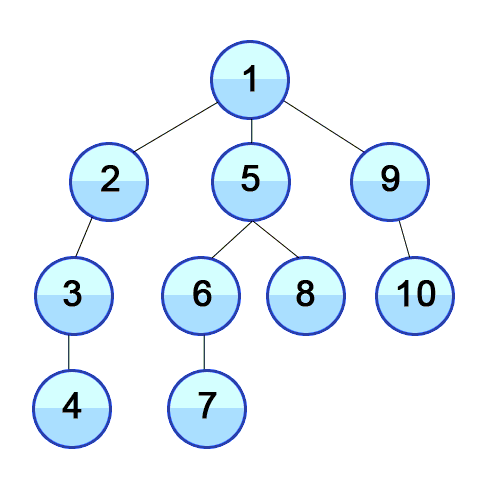
DFS란?
깊이 우선 탐색 알고리즘이다.
위의 gif와 같이 방문하지 않은 노드가 있으면 계속 연결되어 있는 곳으로 깊어지며 탐색하는 알고리즘이다.
원리는 스택(stack)을 이용하여 동작을 한다. 이를 구현하는데 도움을 주는 것은 재귀함수이다.
< 예시 >
#위의 gif의 노드들의 연결상태를 리스트로 표현.
graph = [[],[2,5,9],[1,3],[2,4],[3],[1,6,8],[5,7],[6],[5],[1,10],[9]]
visited = [False]*11
def dfs(graph,v,visited):
visited[v]=True
print(v,end=' ')
for i in graph[v]:
if not visited[i]:
dfs(graph,i,visited)
dfs(graph,1,visited)
output
1 2 3 4 5 6 7 8 9 10
다음과 같이 노드들이 아래쪽부터 탐색 되어짐을 확인할 수 있다.
원리
- dfs 함수는 제일 첫 노드를 읽어드리고 탐색을 한다. 그리고 자신과 인접한(순서상 제일 빠른) 노드를 방문처리한다.
- 재귀함수를 이용하여 인접한 노드중 탐색이 되지 않은 곳은 끝없이 탐색을 하며 방문처리를 한다.
- 노드 탐색은 정점에 도달하였을 때 제일 깊은 곳의 재귀함수가 빠져나온다.
- 3과정을 반복하다 for순회 과정중 아직 탐색을 하지 않은 곳이 있다면 다시 재귀함수가 호출되어 탐색이 되어진다.
따라서 동작의 원리가 스택(stack)이다.
👍장점
- 현 경로상의 노드를 기억하기 때문에 적은 메모리를 사용한다.
- 찾으려는 노드가 깊은 단계에 있는 경우 BFS 보다 빠르게 찾을 수 있다.
👎단점
- 해가 없는 경로를 탐색 할 경우 단계가 끝날 때까지 탐색한다.
- DFS를 통해서 얻어진 해가 최단 경로라는 보장이 없다. DFS는 해에 도착하면 탐색을 종료하기 때문이다.
BFS(Breadth-Fist-Search)
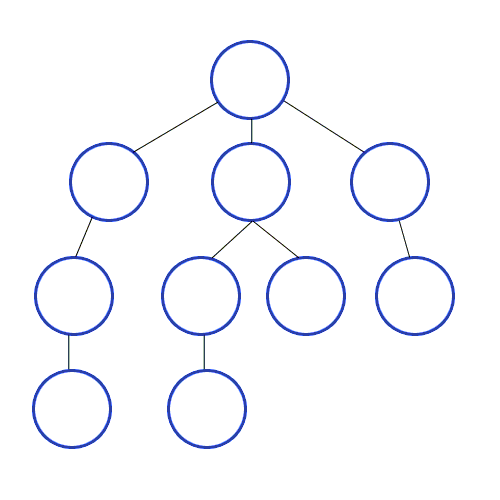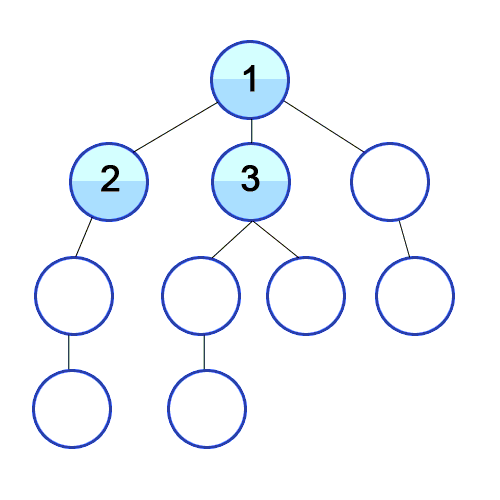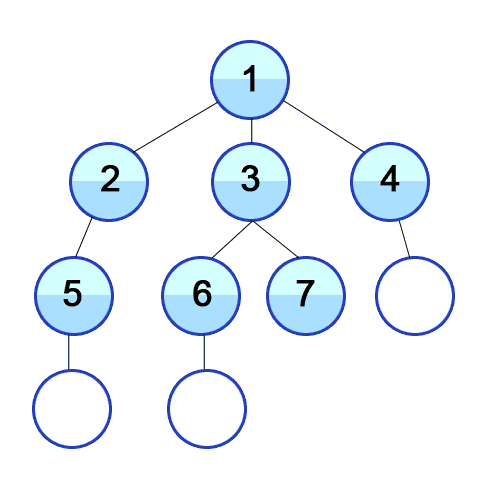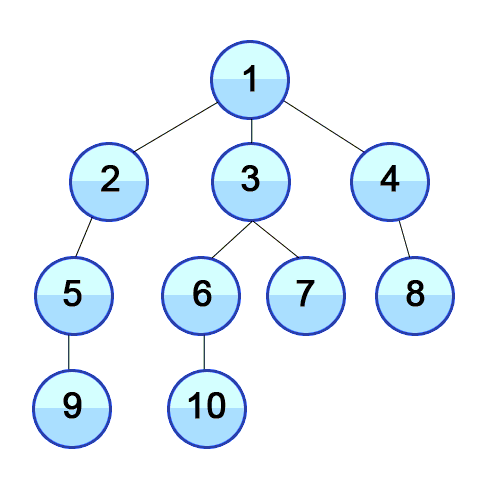
BFS란?
너비 우선 탐색 알고리즘이다.
위의 gif와 같이 가까운 노드들 부터 탐색하는 알고리즘이다.
원리는 __큐(Queue)__를 이용하여 동작을 한다. 이를 구현하는데 도움을 주는 것은 큐(Queue)이다.
< 예시 >
from collections import deque
graph = [[],[2,3,4],[1,5],[1,6,7],[1,8],[2,9],[3,10],[3],[4],[5],[6]]
visited = [False]*11
def bfs(graph,start,visited):
queue = deque([start])
visited[start] = True
while queue:
v = queue.popleft()
print(v, end=' ')
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
bfs(graph,1,visited)
output
1 2 3 4 5 6 7 8 9 10
다음과 같이 가까이 인접한 노드들부터 탐색 되어진다.
원리
- bfs 함수는 제일 첫 노드를 방문처리한다.
- 첫 노드를 queue에서 꺼냄과 동시에 (방문하지 않은)인접한 노드를 queue에 삽입한다.
- queue에서 노드를 하나씩 꺼내며 2.의 과정을 반복한다.
👍장점
- 답이 되는 경로가 여러 개인 경우에도 최단경로임을 보장한다.
- 최단 경로가 존재하면 깊이가 무한정 깊어진다고 해도 답을 찾을 수 있다.
👎단점
- 경로가 매우 길 경우에는 탐색 가지가 급격히 증가함에 따라 보다 많은 기억 공간을 필요로 하게 된다.
- 해가 존재하지 않는다면 유한 그래프(finite graph)의 경우에는 모든 그래프를 탐색한 후에 실패로 끝난다.
- 무한 그래프(infinite graph)의 경우에는 결코 해를 찾지도 못하고, 끝내지도 못한다.
🔥DFS/BFS 연습문제
- [백준] DFS와 BFS: 1260번 ⚡clear
- [백준] 미로탐색: 2178번 ⚡clear
- [백준] 숨바꼭질: 1697번 ⚡clear
- [백준] 유기농 배추: 1012번 ⚡clear
- [백준] 연결 요소의 개수: 11724번 ⚡clear
- [백준] 단지번호붙이기: 2667번 ⚡clear
- [백준] 로또: 6603번 ⚡clear
- [백준] 토마토: 7576번 ⚡clear
- [백준] 나이트의 이동: 7562번 ⚡clear
covenant님의 추천목록을 참고하여 만들었습니다.(출처 아래)
출처/참고
이것이 코딩 테스트다 - 나동빈 저
https://covenant.tistory.com/132
감사합니다🙇♂️
댓글남기기